XBRL Engine Developers Guide
This document describes how to use the AMANA XBRL Engine to utilize XBRL instances and taxonomies.
Used Technologies
AMANA.XBRL.Engine is a class library project based on .NET 4.7.2 which can be easily embedded into any .NET 4.7.2+ project.
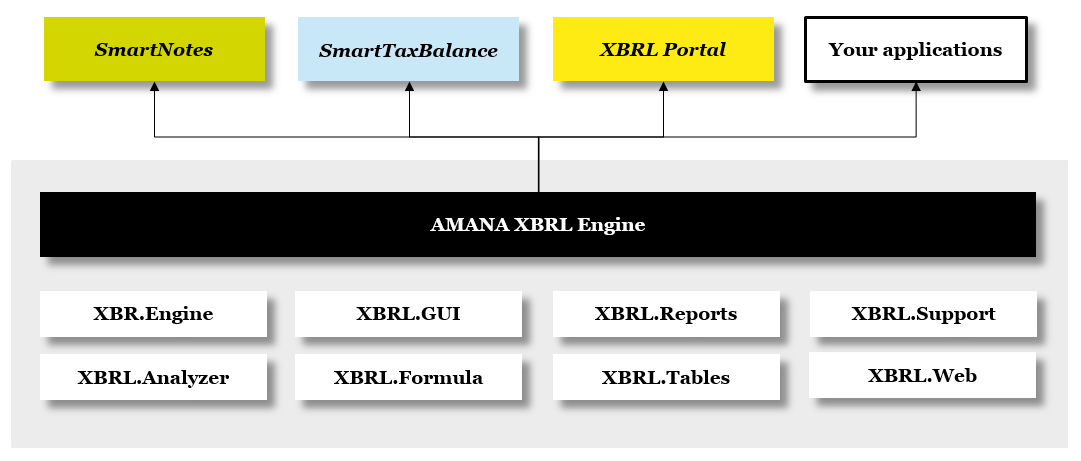
Usually, referenced assemblies are available automatically. However, the following components are used by the AMANA.XBRL.Engine:
- .NET 4.7.2 Framework
- Lightweight XPath2 for .NET Library available at: http://xpath2.codeplex.com/
- DotNetZip Library from the http://dotnetzip.codeplex.com/
- EPPlus Excel Spreadsheets http://epplus.codeplex.com/
- NCalc https://ncalc.codeplex.com/
Generally, all the recent versions of Windows are supported. For more information, refer to the .NET 4.7.2 System Requirements at:
System Requirements for version 4.7.2
Getting started
License File
The AMANA XBRL Engine requires a license file. The Engine will look for the license file at the following locations:
- At the processor’s default XBRL settings folder “%APPDATA%\Roaming\AMANAconsulting”.
- At the processor’s XBRL cache folder, which can be defined in the XBRLSetting’s XBRLFileCachePath property. The default value for this property is “%APPDATA%\AMANAconsulting\XBRLCache”.
- At the location, where the engine’s .dll files are stored.
XBRL Settings File
Certain functionalities of the AMANA.XBRL.Engine library can be controlled from the Settings file (named SmartXBRLSettings.xml) which resides in the AMANAConsulting directory under following path:
%APPDATA%\AMANAConsulting
A typical SmartXBRLSettings.xml file might look like this:
<?xml version="1.0"?>
<XBRLSettings xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<ThrowXBRLExceptionForUnitTesting>false</ThrowXBRLExceptionForUnitTesting>
<MaxValidationExceptionLimit>10000000</MaxValidationExceptionLimit>
<UseProxy>NoProxy</UseProxy>
<ProxyPort>0</ProxyPort>
<ProxyUseAuthentication>false</ProxyUseAuthentication>
<XBRLFileCachePath>C:\Users\user.name\AppData\Roaming\AMANAconsulting\XBRLCache</XBRLFileCachePath>
<ForceOfflineMode>true</ForceOfflineMode>
<FillOffllineCache>true</FillOffllineCache>
<ReDownloadAndOverrideCachedFiles>false</ReDownloadAndOverrideCachedFiles>
<TaxonomyPackageCacheType>Extracted</TaxonomyPackageCacheType>
<DisableAsyncTaxonomyLoading>false</DisableAsyncTaxonomyLoading>
<DisableBinaryCache>true</DisableBinaryCache>
<PreferStreamedPackage>false</PreferStreamedPackage>
<ValidateUTR>false</ValidateUTR>
<CalculationLinkbaseValidationMode>Auto</CalculationLinkbaseValidationMode>
<CalculationLinkbaseExclusions>
<string>www.eba.europa.eu</string>
<string>eiopa.europa.eu</string>
<string>www.bundesbank.de</string>
<string>www.bde.es</string>
<string>www.srb.europa.eu</string>
<string>www.fma-li.li</string>
<string>www.bankingsupervision.europa.eu</string>
<string>www.bankofengland.co.uk</string>
</CalculationLinkbaseExclusions>
<CalculationValidationSeverityErrorThreshold>0.01</CalculationValidationSeverityErrorThreshold>
</XBRLSettings>
There are few settings which might alter the behavior of the Engine:
- ThrowXBRLExceptionForUnitTesting: This setting should not be used in production enviroments, setting it to true causes the XBRL Engine to stop any validation by throwing an exception if an error is detected.
- DisableAsyncTaxonomyLoading: Once enabled, the files of a taxonomy are read asynchronously instead of one after another, which is usually slower. This option can be used if async loading causes issues. Default value is false.
- DisableBinaryCache: When set to true, the fast binary cache is disabled. Default value is false.
- FillOffllineCache: Once set to true, enables the Engine to access remote location where a taxonomy is hosted and download it. The folder path where the taxonomy will be stored, is specified by the XBRLFileCachePath setting.
- ForceOfflineMode: Once enabled, forces the Engine to use the local cache where the taxonomies are located. If the taxonomies are not found, the engine will download them from the internet. The local cache path is specified by the XBRLFileCachePath setting.
- MaxValidationExceptionLimit: Specified in numbers defining the validation message limit. Once limit is reached, the Engine throws an XbrlExceptionLimitReachedException. This setting should have a default value of at least 10000.
- ReDownloadAndOverrideCachedFiles: When enabled, the local cached files in the XBRLCache folder will always be replaced with new ones loaded from the internet. This setting should not be set to true in production envirments, default value is false.
- TaxonomyPackageCacheType: Select in which form the taxonomy packages will be stored. You can choose between None, Extracted and Zip.
- ThrowXBRLExceptionForUnitTesting: Once set to true, forces the Engine to throw a XbrlException if one occurs.
- UseProxy: Once set, forces the Engine to use a Proxy Server in order to access the remote location where the taxonomy is situated. If enabled, the following Properties must be specified:
- ProxyAddress: Must be a valid string.
- ProxyPort: Must be a valid integer.
- ProxyUser: Must be a valid string.
- ProxyPasswordEncrypted: Must be a valid string.
- ProxyUseAuthentication: Must be a valid bool.
- XBRLFileCachePath: Specifies a path to local folder where the taxonomies are stored. This can be different for every client. Please don't forget to modify.
- Calculation Linkbase Validation settings:
- CalculationLinkbaseValidationMode: If set to Auto (default value), the calculation linkbase validation is performed on any XBRL document except those using one of the taxonomies listed in the CalculationLinkbaseExclusions. If the setting is set to Enabled, the validation is always performed, if set to Disabled, it is never performed.
- CalculationValidationSeverityErrorThreshold: This percent value (e.g. 0.01 = 1%) can be used to define a threshold which changes the severity of calculation linkbase inconsistencies to WARNING instead of error. If this setting is set to xsi:nil="true", the severity is not overwritten.
- CalculationLinkbaseValidationMode: If set to Auto (default value), the calculation linkbase validation is performed on any XBRL document except those using one of the taxonomies listed in the CalculationLinkbaseExclusions. If the setting is set to Enabled, the validation is always performed, if set to Disabled, it is never performed.
- ValidateUTR: If this setting is set to true (default), the Unity Type Registry is performed as part of the normal XbrlDocument validation.
- Taxonomy Packages settings:
- TaxonomyPackageCacheType: If the value is set to Extract, the Taxonomy Packages ZIP archives are extracted to the XBRLCache folder. However, this can cause issues for very long filenames. If the value is set to Zipped, the ZIP archived will be opened as streams, which can cause higher memory consumption. If the setting is set to None, no XBRL Taxonomy Packages are used at all while loading XBRL taxonomies.
- PreferStreamedPackage: If this setting is set to true, the XBRL Engine will resolve files from the XBRL Taxonomy Package ZIP archives first before trying to resolve it from the local XBRL Cache folder. Default value is false.
- TaxonomyPackageCacheType: If the value is set to Extract, the Taxonomy Packages ZIP archives are extracted to the XBRLCache folder. However, this can cause issues for very long filenames. If the value is set to Zipped, the ZIP archived will be opened as streams, which can cause higher memory consumption. If the setting is set to None, no XBRL Taxonomy Packages are used at all while loading XBRL taxonomies.
The settings can be stored as an XML file using it’s static Save method:
var settings = new XbrlSettings(); XbrlSettings.Save(settings, @"C:\path\settings.xml");
The XbrlSettings class also provides a method for loading such an XML file:
var settings = XbrlSettings.Load(@"C:\path\settings.xml");
XBRL Offline Cache
The XBRL Offline Cache is a built-in functionality of the AMANA.XBRL.Engine allowing the Taxonomy Discovery Process to process local versions of taxonomies. This feature speeds up the entire discovery process in comparison with the online mode. Prior to running taxonomy discovery against local data (either processing taxonomy or instance), the taxonomy has to be locally cached (in other words, saved on the local file system). The path to the local cache folder is specified by the XBRLFileCachePath property. In order to activate the feature, the following steps should be undertaken:
- Set FillOffllineCache property to true. This enables the Engine to save taxonomies on the local file system as soon as they are loaded from the internet. By activating this property, all files downloaded from a remote source will be stored in the cache folder.
- Set the ForceOfflineMode. This option forces the AMANA.XBRL.Engine to access taxonomies from local file system.
The following example shows how a remotely referenced file will then be stored in the local cache folder.
Remote reference:
http://www.eba.europa.eu/eu/fr/xbrl/crr/fws/corep/its-2014-05/2015-02-16/mod/corep_ind.xsd
Local folder path:
C:\Users\user.name\AppData\Roaming\AMANAconsulting\XBRLCache\www.eba.europa.eu\eu\fr\xbrl\crr\fws\corep\its-2013-02\2014-07-31\mod\corep_ind.xsd
Taxonomy Caching Processor
The Taxonomy Caching Processor provides faster access to taxonomies that are referenced by a remote Uri by keeping them cached in the memory after they are opened for the first time. It is highly recommended to use this feature for servers or in constantly running applications. By default, cached taxonomies removed from the memory after 2 days or when the memory usage of the system reaches 95%. The TaxonomyCachingProcessor provides a ReadXbrltaxonomy function just like the XbrlProcessor. The following example shows how to open a taxonomy with the TaxonomyCachingProcessor. When the same taxonomy is read at a later point, it will be loaded directly from the cache in the memory.
Loading of XBRL Taxonomies and Reports
Processor
The Processor class is responsible for loading XBRL documents, like XBRL taxonomies or XBRL instance files. The default constructor will try to read the XBRL settings file from the default settings location “%APPDATA%/Roaming/AMANAconsulting/SmartXBRLSettings.xml”:
var processor = new Processor();
The path to the XBRL settings file can also be passed as a string:
var processor = new Processor(@"C:\path\XBRLSettings.xml");
You can also create an XbrlSettings object, which keeps the settings and passes it to the constructor. The settings from this settings object will be used instead of the deafult settings. You can access the processor’s settings using its Settings property.
var xbrlSettings = new XbrlSettings(); var processor = new Processor(xbrlSettings);
Taxonomy Caching Processor
The Taxonomy Caching Processor provides faster access to taxonomies that are referenced by a remote Uri by keeping them cached in the memory after they are opened for the first time. It is highly recommended to use this feature for servers or in constantly running applications. By default, cached taxonomies removed from the memory after 2 days or when the memory usage of the system reaches 95%. The TaxonomyCachingProcessor provides a ReadXbrltaxonomy function just like the XbrlProcessor. The following example shows how to open a taxonomy with the TaxonomyCachingProcessor. When the same taxonomy is read at a later point, it will be loaded directly from the cache in the memory.
TaxonomyCachingProcessor taxCacheProcessor = new TaxonomyCachingProcessor();
Uri uri = new Uri("http://www.eba.europa.eu/eu/fr/xbrl/crr/fws/ae/cir-680-2014/2018-03-31/mod/ae_con.xsd");
XbrlTaxonomy tax = taxCacheProcessor.ReadXbrlTaxonomy(uri);
How to read an XBRL Taxonomy
AMANA.XBRL.Engine allows loading taxonomies from both Url (remote location) and local file system. A taxonomy can be loaded using the processor’s ReadXbrlTaxonomy method. You can pass the path to a locally stored taxonomy, which will be read by the processor:
var taxonomy = processor.ReadXbrlTaxonomy(
@"C:\EIOPA\eiopa.europa.eu\eu\xbrl\s2md\fws\solvency\solvency2\2015-10-21\mod\ars.xsd");
In this case, the entry point of the taxonomy will be the file path! This can lead to problems, e.g. when generating an instance document. It is recommended to use the entry point of the desired taxonomy and e.g. pass it as an URL. This can be done by passing the entry point to the processor, which will then download the taxonomy:
var taxonomy = processor.ReadXbrlTaxonomy(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
The URL can also be passed as an URI object.
var uri = new Uri(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
var taxonomy = processor.ReadXbrlTaxonomy(uri);
When loading a XBRL taxonomy via an URL, the processor can be configured to first look for the XBRL schema files in the local cache. If the schema files are not found, it will try to load the files via the internet. By default, all downloaded files are stored in the XBRL cache folder. The cache folder, proxy settings and other settings can be configured in the Processor’s settings file.
Taxonomy Validation
A loaded taxonomy can also be validated to check if it fulfills the XBRL specification by calling it’s Validate method, which conducts explicit XML schema validation:
var processor = new Processor();
var taxonomy = processor.ReadXbrlTaxonomy(
"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2015-10-21/mod/ars.xsd");
taxonomy.Validate();
var validationResults = taxonomy.TaxonomyResultSet.GetItems().ToList();
The Validate(GenericLinkbaseContainer container = null) function has an optional parameter of type GenericLinkbaseContainer, which contains all generic links. If it exists, all the contained links are validated as well. After calling the Validate method, the TaxonomyResultSet property of the XbrlTaxonomy will be filled. Each item within this result set is a single validation error. To get all items, use the TaxonomyResultSet.GetItems() method, which will return an IEnumerable of IValidationResult objects. The most important properties of IValidationResult are:
- IsValid: Specifies whether the taxonomy is valid or not.
- Message: A validation error message.
- Message: Specifies validation message.
- Severity: Specifies message severity. Following Enum values can only be assigned with the property:
Error
Warning
Information
- Type: Specifies the validation type which is restricted to one of the following (Enum):
- TaxonomySpec21
- TaxonomyXml
- TaxonomySec
InstanceXml
- InstanceSpec21
- InstanceSec
- InstanceEBilanz
- TaxonomyTableLinkbaseSpec
- InstanceTableLinkbaseSpec
- TaxonomyDimensionSpec
- InstanceDimensionSpec
- InstanceFormulaSpec
- TaxonomyFormulaSpec
- TaxonomyExtensibleEnumerations
- InstanceExtensibleEnumerations
- FilingRules
- InlineXbrl
- InlineXbrlSchema
- InlineXhtmlSchema
- ReportGeneration
- ReportMapping
- Other
- RuleId: The ID of the rule specified by the taxonomy.
- Rule: The rule definition itself.
How to load an XBRL Instance Document
To load an XBRL instance file, use the Processor’s LoadXbrlDocument method. For example this will load a locally stored file:
var xbrlDocument = processor.LoadXbrlDocument(@"C:\path\xbrlInstance.xml");
It is also possible to pass a Stream or a XmlReader to this method:
using (var stream = new FileStream(@"C:\path\xbrlInstance.xml", FileMode.Open))
{
var xbrlDocument = processor.LoadXbrlDocument(stream);
}
How to load an Inline XBRL Instance Document
To load an iXBRL XHTML file, use the Processor’s LoadInlineXbrlDocument method. For example this will load a locally stored file:
var xbrlDocument = processor.LoadInlineXbrlDocument(@"C:\path\ixbrl-report.xhtml");
It is also possible to pass a Stream or an XmlReader to this method:
using (var stream = new FileStream(@"C:\path\ixbrl-report.xhtml", FileMode.Open))
{
var xbrlDocument = processor.LoadXbrlDocument(stream);
}
To load multiple XHTML documents, the InlineXbrlDocument class can be called directly:
List<XmlDocument> docs = new List<XmlDocument>();
foreach (string name in Directory.GetFiles("c:\reports", "*.xhtml"))
{
var d = new XmlDocument(_processor.NameTable);
d.Load(name);
docs.Add(d);
}
InlineXbrlDocument ixbrlDoc = InlineXbrlDocument.Load(_processor, docs);
How to load XBRL Instance Documents from Report Packages
The report packages standard allows packaging of XBRL instance documents together with taxonomy extensions. To load an report package, the ReportPackageLoader class can be used:
using (ReportPackageLoader packageLoader = new ReportPackageLoader("reportpackage.zip", _processor))
{
if (!string.IsNullOrEmpty(packageLoader.XbrlFileName))
_instanceDocument = packageLoader.LoadXbrlDocument();
else if (packageLoader.XhtmlFileNames.Any())
_inlineXbrlDocument = packageLoader.LoadInlineXbrlDocument();
}
Validation of XBRL Documents
XBRL Instance Document Validation
When loading an instance document, the XBRL taxonomies which are referenced by the instance, will also be loaded. The instance file can be validated against the XBRL schema and validation rules defined in the referenced taxonomy files by calling the method XbrlDocument.Validate(bool validateXbrlTaxonomies, bool attachResultsToFacts, GenericLinkbaseContainer container = null):
The Validate() method accepts the following parameters:
- bool validateXbrlTaxonomies: Boolean parameter specifing whether the taxonomy, which the provided instance conforms to, should be validated as well.
- bool attachResultsToFacts: If set to true, all fact related validation results will be included in the Fact.ValidationResults List.
- GenericLinkbaseContainer container: The container which stores all generic links of the XBRL taxonomy. Can usually be ignored.
There are two more overloads:
- Validate(): Skips the validation of the XbrlTaxonomy itself (equal to Validate(true, false) ).
- Validate(bool validateXbrlTaxonomies, GenericLinkbaseContainer container = null): The fact related validation results will not be included in the Fact.ValidationResults list.
The method can be called as follows:
XbrlDocument xbrlDoc = new XbrlDocument(); xbrlDoc.Load(@"c:\testInstanz.xml"); xbrlDoc.Validate(); // Skips the validation of the XbrlTaxonomy itself
The Validate() method conducts explicit XML schema validation. The results of the validation can be easily retrieved using GetItems() method of XbrlDocument.DocumentResultSet property:
IEnumerable<XbrlMessage> messages = xbrlDoc.DocumentResultSet.GetItems();
Formula Validation
The AMANA.XBRL.Engine supports formula validation per XBRL Formula Linkbase specification. The Formula validation can be simply initiated by the extension method ValidateIncludingFormula() of the XbrlDocument class:
using AMANA.XBRL.Engine.Plugin.FormulaLinkbase;
var processor = new Processor();
XbrlDocument instanceDocument = processor.LoadXbrlDocument(@"C:\path\instance.xbrl");
instanceDocument.ValidateIncludingFormula(
validateTaxonomies: false,
verbose: false,
attachResultsToFacts: false,
includeIds: new List<string>(),
excludeIds: new List<string>(),
enableTPL: true);
IEnumerable<IValidationResult> results = instanceDocument.DocumentResultSet.GetItems();
This method ValidateIncludingFormula first performs XBRL instance validation with optional taxonomy validation because the instance document has to be valid according to XML and XBRL standards before being able to perform further formula validation. If XBRL instance validation fails, the formula validation will not run. The result of the formula validation is included in the DocumentResultSet property of the XbrlDocument class.
The behaviour of formula validation can be controlled using the following function parameters:
- validateTaxonomies: The parameter specifies whether the taxonomy, which the provided instance conforms to, should be validated as well. The taxonomy validation is not necessary for performing formula validation.
- verbose: Once enabled, forces the validator to display/log all messages generated during the formula validation. Can be used for detailed analysis.
- attachResultsToFacts: if enabled, forces formula processor attach errors to related facts for future references. It allows tracking errors by each fact for user UI for example.
- InclusionIds: The list of string specifying Validation Formula IDs which should be performed in formula validation.
- ExclusionIds: On the contrary, the ExclusionIds specifies the list of Validation Formula IDs which should be skipped during the formula validation.
- EnableTPL: Enables using .NET Task Parallel Library to speed up Formula processing performance. This option is enabled by default.
Filing Rule Validation
Many authorities define filing rules, a set of additional rules which are not defined in the XBRL taxonomy itself. Hence those rules are manually programmed in the Engine DLL files. If the filing rules are updated, an update of the engine will be needed. To run file rule validaitons for an XBRL instance document, an FilingRulesValidator object must be created. In the following codeblock, a method ValidateInstance is written which demonstrate how to use the FilingRulesValidator
private void ValidateInstance(XbrlInstance instance)
{
var validator = new FilingRulesValidator();
validator.LoadRules(Regulator.EBA4_3, false);
List<FilingRuleValidationMessage> validationResults = validator.Validate(instance);
foreach (var result in validationResults)
Console.WriteLine($"{result.RuleId}: {result.Message}");
}
After creating the FilingRulesValidator, the rules which should be validated are loaded via its LoadRules method. The rules are validated using the method Validate. Validation results are returned as a List of FilingRuleValidationMessageObjects. The following list shows the methods of the class FilingRulesValidator:
| Method | Description |
|---|---|
| LoadRules(Regulator, bool) | Loads the rules which should be validated. The first parameter defines the regulator and version of a specific filing rule set. Regulator is a enum defined in the Engine. The second parameter defines if the rule for validating the file name should also be loaded. |
| LoadRules(Regulator, List<string>, bool, bool) | Loads the rules which should be validated. The first parameter defines the regulator and version of a specific filing rule set. As second parameter, a list of validation rule names can be passed. If the third parameter is set to true, only those rule, which name contains any string in the list of validation rules will be validated. If set to false, rules whose name contains any of the passed strings will be excluded. The last boolean parameter defines if the rule for validating the file name should also be loaded. |
| GetRuleNames(Regulator, bool) | Gets the name of all rules for a specific rule set. The first paramter defines the regulator and version of a specific rule set. The second parameter defines if the rule for validating the file name should also be loaded. |
| Validate(XbrlInstance) | Validates the instance documents using the rules which were previously loaded using the LoadRules method. |
The FilingRuleValidationMessage class has the following attributes:
| Name | Description |
|---|---|
| Name | The name of the corresponding filing rule. |
| IsValid | Indicates if the instance fulfills the filing rule. |
| IsException | Indicates if an Exception occured during the validation of the filing rule. |
| Message | The message which indicates the reason why the instance does not fulfill the filing rule. |
| RuleId | The ID of the corresponding filing rule. |
| Rule | The name of the corresponding filing rule. |
| Type | Returns always the enumaration value ValidationTypes.XbrlValidaitonType.FilingRules. |
| Severity | Returns the severity of the error. The severity is a value of the enum ValidationTypes.Severity, which can have one of the following values: Error, Warning, Information. |
Extracting Data from XBRL Instances
The XbrlDocument class provides the XbrlInstances property, which contains the instances data. The most important properties are:
List<FactBase> Facts: Facts, i.e. reported data, of the instance document.
Dictionary<XmlQualifiedName, List<FactBase>>BaseFactsByElement: Facts by the XML qualified name of the corresponding concept/metric.
List<Context> Contexts: All contexts defined in the instance document.
List<Units> Units: All units defined in the instance document.
List<XbrlTaxonomy> Schemas: The XBRL taxonomies/schemas, which are used by the instance document.
Generating XBRL Instance
AMANA.XBRL.Engine allows a smooth XBRL Instance generation process. The instance generation process can easily be organized into 4 logical steps:
- Create Contexts
- Create Units
- Create Facts
- Create Footnotes
First, an object of type XbrlDocument containing an XbrlInstance must be created:
// Read a taxonomy for which an XBRL instance should be created. // In this example, the Solvency II ARS taxonomy version 2.4 is loaded. var processor = new Processor(); XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy(@"http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd"); // Create an XBRL document refering to the taxonomy loaded previously XbrlDocument document = processor.CreateXbrlDocument(taxonomy) // Get the XBRL instance from the created document XbrlInstance instance = document.Instance;
Contexts
XBRL Context is represented by the Context class. A context element contains information about the Entity, the period and dimensional information of reported facts. Each context within an instance has a unique ID.
Entity Information
There are two relevant entity information, which are reported in every context node:
- Identifier: An ID to identify an entity, e.g. a LEI code or SEC's Central Index Key (CIK).
- Identifier scheme: An URI which represents the type of ID used, e.g. http://standards.iso.org/iso/17442 for LEI codes or http://www.sec.gov/CIK for SEC's CIK.
Period Information
There are three different types of periods which can be expressed:
- Instant: A point in time. Can be used to express a value for a metric in a specific point in time.
- Duration: A period with a specified beginning and ending. Can be used to express the change of a value during a specified period.
- Forever: Can be used to express that a value is always valid.
Dimensional Information
The context also contains dimensional information from explicit and typed dimensions. Those are either grouped within a scenario or a segment. If an element in the taxonomy is the primary item of a hypercube, the context must contain dimension information according to the hypercube. There are two types of dimensions:
- Explicit dimension: An explicit dimension defines a set of valid values which can be used for this dimension, e.g. a dimension "Country" may list all countries which can be used. Those values are also called "dimension members".
- Typed dimension: For typed dimensions any value can be used, e.g. a table in which a row for each instrument should be reported can include a dimension "Instrument codes".
A single context can contain both, explicit and typed dimensions.
Example 1 - Multiple Explicit Dimensions
Explicit dimensions will be explained using the example below, which displays a role from the definition linkbase of the full IFRS entry point from 2019.
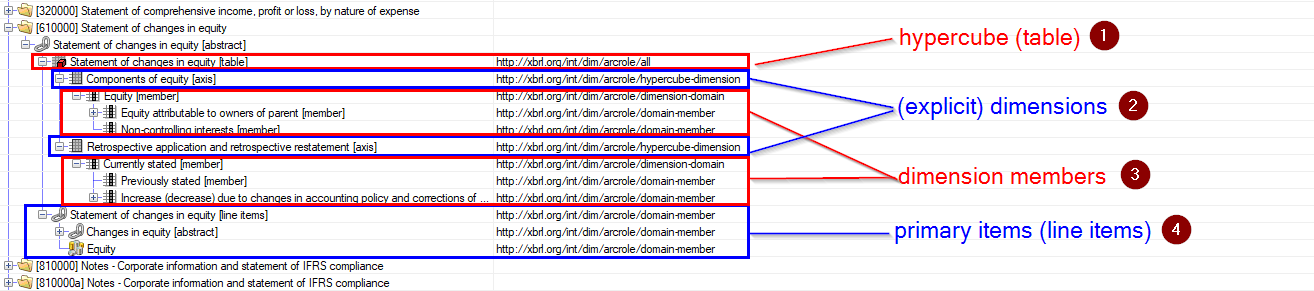
The role has the hypercube "Statement of changes in equity" (1). This cube is added to the role using an arc with the role "http://xbrl.org/int/dim/arcrole/all". This arcrole states that if a value for any primery item (4) is reported, you have to report also values for each dimension which is part of the hypercube in the value's context. The hypercube has two explicit dimensions (2): "Components of equity" and "Retrospective application and retrospective restatement". So for both dimensions one of it's dimension members (3) must be reported. E.g. for the dimension "Components of equity" the member "Non-controlling interests" and for the dimension "Retrospective application and retrospective restatement" the member "Previously stated" could be reported.
It is possible to report the line item "Equity" multiple times for the same period, but with different dimension member combinations.
Example 2 - Typed Dimensions
Typed dimensions will be explained using the example below, which displays a role from the Solvency II ARS taxonomy from version 2.4:
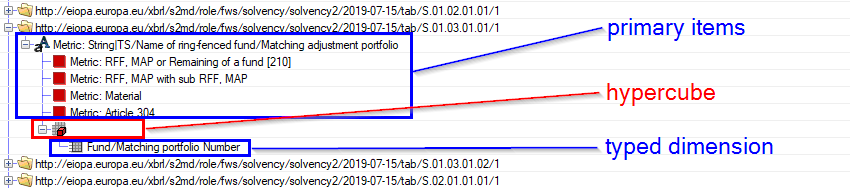
Again a list of primary items is linked with a hypercube. This Hypercube has only one typed dimension "Fund/Matching portfolio number". So if a value for "Metric: Material" should be added, its context must include the dimension "Fund/Matching portfolio Number" and a value for this dimension. Because this dimension is a typed dimensions, there are no predefined values (i.e. dimension members).
Adding Contexts
For adding Contexts, it is recommended to use the method AddInstantContext or AddDurationContet defined in the XbrlInstance class. Those methods create a context with either a instant period or a duration period and add it directly to the instance. The following code creates an instance document for EIOPA's ARS taxonomy and adds a context and a fact for reporting the company name:
// Load the taxonomy
Processor processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create a new document (report) for the taxonomy
XbrlDocument xbrlDocument = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the company
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
Context context;
// Check the element's period type to determine if a context with an instant period or a context with a duration period must be created
if (undertakingNameElement.PeriodType == Element.ElementPeriodType.Instant)
{
// Create a new context with a instant context
context = xbrlDocument.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// instant date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
}
else
{
// Create a new context with a duration context
context = xbrlDocument.Instance.AddDurationContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// start date of the new context
new DateTime(2020, 1, 1),
// end date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
}
// Add a fact for the element using the previously generated context
xbrlDocument.Instance.AddTextualFact(context, undertakingNameElement, "AMANA consulting GmbH");
The example below demonstrates how to create a context with explicit dimensions based on the example "Example 1 - Multiple Explicit Dimensions" in the chapter "Dimensional Information" above:
// Load the taxonomy
var processor = new Processor();
var taxonomy = processor.ReadXbrlTaxonomy("http://xbrl.ifrs.org/taxonomy/2019-03-27/full_ifrs_entry_point_2019-03-27.xsd");
// Create a new document (report) for the taxonomy
var document = XbrlDocument.Create(processor, new List<XbrlTaxonomy> { taxonomy });
// Get the dimension element & the member element for the axes
var firstAxis = taxonomy.GetElementByLocalName("ComponentsOfEquityAxis");
var memberForFirstAxis = taxonomy.GetElementByLocalName("NoncontrollingInterestsMember");
var secondAxis = taxonomy.GetElementByLocalName("RetrospectiveApplicationAndRetrospectiveRestatementAxis");
var memberForSecondAxis = taxonomy.GetElementByLocalName("PreviouslyStatedMember");
// Create a dictionary for the dimensions and members
// Each entry in the dictionary is a combination of a dimension and it's member
// The first element is the name of the dimension
// The second element is the name of the member
// The order of the elements in this dictionary is not relevant
var explicitDimensions = new Dictionary<XmlQualifiedName, XmlQualifiedName>();
explicitDimensions.Add(firstAxis.QualifiedName, memberForFirstAxis.QualifiedName);
explicitDimensions.Add(secondAxis.QualifiedName, memberForSecondAxis.QualifiedName);
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContextId",
// instant date of the new context
new DateTime(2019, 12, 31),
// identification code of the reporting entity
"AMANA consulting GmbH",
// type of the identification code
"http://www.sec.gov/CIK",
// explicit dimensions
explicitDimensions,
// typed dimensions
null,
// dimension container, usually always scenario must be used
DimensionContainer.Scenario
);
The example below demonstrates how to create a context with explicit dimensions based on the example "Example 2 - Typed Dimensions" in the chapter "Dimensional Information" above:
// Load the taxonomy
var processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create an XBRL instance document based on the loaded taxonomy
XbrlDocument document = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the fund/portfolio
Element fundPortfolioNameElement = taxonomy.GetElementByLocalName("si1376");
// Get the dimension element
var typedAxis = taxonomy.GetElementByLocalName("FN");
// Create a dictionary for the dimensions and values
// Each entry in the dictionary is a combination of a dimension and it's value
// The first element is the name of the dimension
// The second element is the value for this dimension
// The order of the elements in this dictionary is not relevant
var typedDimensions = new Dictionary<XmlQualifiedName, string>();
typedDimensions.Add(typedAxis.QualifiedName, "typedValue");
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContextId",
// instant date of the new context
new DateTime(2019, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442",
// explicit dimensions
null,
// typed dimensions
typedDimensions,
// dimension container, usually always scenario must be used
DimensionContainer.Scenario
);
// Add a fact for the element using the previously generated context
document.Instance.AddTextualFact(context, fundPortfolioNameElement, "fact value");
The following methods defined in the class XbrlInstance can be used for creating and adding a new context to an instance:
| Method | Description |
|---|---|
| AddInstantContext(string, DateTime, string, string) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddInstantContext(string, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddInstantContext(string, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer, bool) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, DateTime, DateTime, string, string) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, Datetime, DateTime, sting, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
| AddDurationContext(string, DateTime, DateTime, string, string, Dictionary<XmlQualifiedName, XmlQualifiedName>, Dictionary<XmlQualifiedName, string>, DimensionContainer, bool) | Adds an context with an instant period to the XBRL instance. The parameters are:
|
Units
XBRL units define XBRL fact measurements. E.g. a specific currency or pure, which is used for percentages. Units consist of numerators and optionally denominators. In most cases, only a numerator is needed to express a specific unit. E.g. If the unit of a fact is Euros, the unit consists of the numerator Euro. No denominator is needed in this case.
Denominators are only needed to express divisions. E.g. to express the earnings per share in euro, a unit is nedded with Euro as numerator and shares as denominator.
A numerator and a denominator is a XmlQualifiedName. The constant XbrlBaseConstants.Iso4217, defined in AMANA.XBRL.Engine as "http://www.xbrl.org/2003/iso4217", can be used as namespace for adding monetary units. To create a new unit and add it to an existing instance, use the method AddUnit defined in the class XbrlInstance. The following code adds the unit "EURO" to an existing instance:
XmlQualifiedName unitCode = new XmlQualifiedName("EUR", XbrlBaseConstants.Iso4217);
var numerators = new List<XmlQualifiedName>();
var denominators = new List<XmlQualifiedName>();
numerators.Add(unitCode);
Unit unit = instance.AddUnit("EURO", numerators, denominators);
This code will add the following XML node to the instance document:
<xbrli:unit id="EURO"> <xbrli:measure>iso4217:EUR</xbrli:measure> </xbrli:unit>
The following overloads for this method exists:
| Method | Description |
|---|---|
| AddUnit(string, XmlQualifiedName) | Adds an unit to the instance. The parameters are:
|
| AddUnit(string, List<XmlQualifiedName>) | Adds an unit to the instance. The parameters are:
|
| AddUnit(string, List<XmlQualifiedName>, List<XmlQualifiedName>) | Adds an unit to the instance. The parameters are:
|
Facts
A XBRL fact is represented by the Fact class. Most facts are either numeric or textual, depending on the value which can be reported for the fact's metric. The metric/element from the XBRL taxonomy has a data type which defines what kind of values can be reported for this metric. Examples for types of numeric elements are:
- monetary
- percent
- pure
- decimal
- integer
Examples for types of textual elements:
- QName
- enumeration
- date
- boolean
- string
The class XbrlInstance features two methods to add mentioned facts: AddMonetaryFact for adding numeric facts and AddTextualFact for adding textual facts.
| Method | Description |
|---|---|
| AddNumericFact(Context factContext, Unit factUnit, Element factElement, decimal value, int? decimals, int? precision = null, bool infiniteDecimals = false, string elementId = "") | Adds a numeric fact to the instance document. The parameters are:
|
| AddNumericFact(Context factContext, Unit factUnit, Element factElement, decimal value, string elementId = "") | Adds a numeric fact to the instance document with the decimal attribute set to "INF" which states that the exact value is reported. The parameters are:
|
| AddTextualFact(Context factContext, Element factElement, string value, string elementId ="") | Adds a fact to the instance document and sets the fact's value as value of the XmlNode.Value property. The value will be parsed (e.g. "&" becomes "&" and "<" becomes "<"). If the value is already parsed and should not be parsed a second time, use the method AddEscapedTextualFact instead. The parameters are:
|
| AddEscapedTextualFact(Context factContext, Element factElement, string value, string elementId = "") | Adds a fact to the instance document and sets the fact's value as value of the XmlNode.InnerXml property. The value will not be parsed. If the value should be parsed, use the method AddTextualFact instead. The parameters are:
|
| AddNilFact(Context factContext, Element factElement, bool nil, string elementId = "") | Adds a new fact with the attribute xsi:nil to the XBRL instance document. If necessary, a nil fact can be added to explicitly state that no value is reported by setting the value of the xsi:nil attribute to true. If no value can be reported for a certain metric (element) from the XBRL taxonomy, usually no fact at all is reported. Regulators usually define if and in which cases the usage of xsi:nil="true" is allowed. Usually it is not necessary to add the xsi:nil fact attribute if it's value is false. The parameters are:
|
| AddNilFact(Context factContext, Unit factUnit, Element factElement, bool nil, string elementId = "") | Adds a new fact with the attribute xsi:nil to the XBRL instance document. If necessary, a nil fact can be added to explicitly state that no value is reported by setting the value of the xsi:nil attribute to true. If no value can be reported for a certain metric (element) from the XBRL taxonomy, usually no fact at all is reported. Regulators usually define if and in which cases the usage of xsi:nil="true" is allowed. Usually it is not necessary to add the xsi:nil fact attribute if it's value is false. The parameters are:
|
The following example illustrates how to create and save a new XBRL instance for Solvency II ARS Version 2.4 and add a new textual fact for reporting the name of the reporting entity:
// Load the taxonomy
Processor processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create a new instance document for the taxonomy
XbrlDocument xbrlDocument = processor.CreateXbrlDocument(taxonomy);
// Get the element with the name si1376, which is the element used for reporting the name of the company
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
// Create a new instant context for the element.
Context context = xbrlDocument.Instance.AddInstantContext(
"instantContext",
new DateTime(2020, 12, 31),
"LEI/SAMPLELEICODE",
"http://standards.iso.org/iso/17442");
// Add a fact for the element using the previously generated context.
xbrlDocument.Instance.AddTextualFact(context, undertakingNameElement, "AMANA consulting GmbH");
// Save the XBRL instance document.
xbrlDocument.Save(@"C:\path\instance.xbrl");
Footnotes
Footnotes are additional information to reported facts. The screenshot below shows a fact within the XBRL instance document including a single footnote:
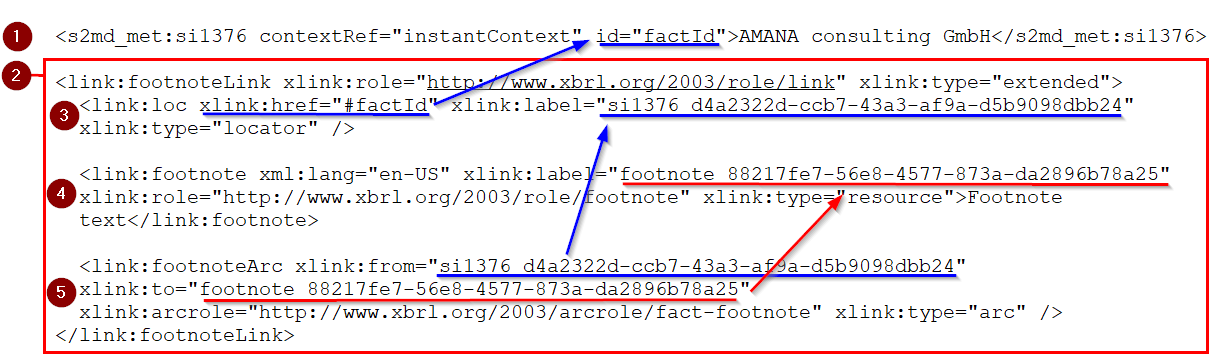
The following parts participate in this case:
- The fact itself: All facts for which a footnote should be assigned need an ID. In this case the ID is "factId".
- A footnote linkbase: All footnotes are stored within a separate block within the instance document.
- A locator: The locator represents the fact within the footnote linkbase. The locator's xlink:href attribute contains the ID of the fact which it represents. It also has a xlink:label attribute which is used by other elements to refer to this locator.
- A footnote: The footnote itself. Within the XML node is the actual text of the footnote. The footnote has also a xlink:label attribute which is used by other elements to refer to this footnote.
- A footnoteArc: The footnote arc connects a footnote with a locator. The value of the attribute xlink:from is the xlink:label of the locator, the value of the attribute xlink:to is the xlink:label of the footnote. The locator contains a reference to the reported fact, such a link between footnote and fact is created.
Locators and Footnotes can be reused:
- If a fact has multiple footnotes, only one locator is needed. Then for each footnote a footnoteArc is added to the instance document. Those footnoteArcs have all the same value for the xlink:from attribute, because they are referring to the same locator. Only the value of the xlink:to attribute differs, because they are referring to different footnotes.
- If the same footnote is used for multiple fact, e.g. all values within a column for a reported table should get the same footnote, only one footnote is needed. In this case for each fact a footnoteArc is added to the instance document. The value for the xlink:from attribute are the labels of the facts' locators, but the value of the xlink:to attribute for all those footnoteArcs is the xlink:label of the footnote.
The following code illustrates how to add a footnote to an XBRL instance document:
// Load the taxonomy.
var processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy("http://eiopa.europa.eu/eu/xbrl/s2md/fws/solvency/solvency2/2019-07-15/mod/ars.xsd");
// Create an XBRL instance document based on the loaded taxonomy.
XbrlDocument document = processor.CreateXbrlDocument(taxonomy);
// Add a fact to the document.
Element undertakingNameElement = taxonomy.GetElementByLocalName("si1376");
Context context = document.Instance.AddInstantContext(
// ID of the new context, which must be unique for the current document
"instantContext",
// instant date of the new context
new DateTime(2020, 12, 31),
// identification code of the reporting entity
"LEI/SAMPLELEICODE",
// type of the identification code
"http://standards.iso.org/iso/17442");
Fact fact = document.Instance.AddTextualFact(
// The context of the reported value.
context,
// The element for which the value is reported.
undertakingNameElement,
// The value which should be reported for the element.
"AMANA consulting GmbH",
// Facts need an ID so that a footnote can be linked to it.
// The ID must start with a letter.
"factId");
// All footnotes within an instance document are stored within a separate container
// called FootnoteLink
FootnoteLink footnoteLink = document.Instance.AddFootnoteLink();
// A locator for this fact is added to the FootnoteLink.
// This locator refers to the fact which is passed to the method as parameter.
FootnoteLocator factLocator = footnoteLink.AddLocator(fact);
// When adding the actual footnote, the language of the footnote must be specified.
var footnoteLanguage = new CultureInfo("en-US");
Footnote footnote = footnoteLink.AddFootnote(footnoteLanguage, "Footnote text");
// A link between the Footnote and the fact's locator is created.
// It is possible to create multiple links using the same footnote (i.e. the same footnote is linked to different values).
// It is possible to create multiple links using the same fact locator (i.e. the same fact has multiple footnotes).
footnoteLink.AddFootnoteArc(factLocator, footnote);
Tagging of XHTML Documents to generate Inline XBRL Instances
The class InlineXBRLInstanceGenerator can be used to generate InlineXBRLDocuments, which means it adds XBRL Tags to existing XHTML document. The XBRL Engine does not include the XHTML editor. In order to generate an InlineXBRLInstanceGenerator, a processor object as well as the XBRLTaxonomy is required. Any XmlDocument class object can be used to apply tags to. It is important that the XHTML document is complient to its iXBRL XHTML scheme. In the following examples, a small-inline.docx.xhtml file is used.
Processor processor = new Processor();
XbrlTaxonomy taxonomy = processor .ReadXbrlTaxonomy("http://xbrl.ifrs.org/taxonomy/2017-03-09/full_ifrs_mc_doc_entry_point_2017-03-09.xsd");
XmlDocument document = new XmlDocument();
document.Load("small-inline.docx.xhtml");
InlineXbrlInstanceGenerator inlineGenerator = new InlineXbrlInstanceGenerator(processor, document, new List<XbrlTaxonomy> { taxonomy });
Tag Inline Facts
To tag numbers and texts in XHTML document, the appropriate XmlElement must be selected either with XPath or any other way. After that the iXBRL Tag can be applied to it. Optionally, the method TagNonFractionItem() accepts a format parameters as XmlQualifiedName, that must match the formats defined in the transformation registries, in order to be tagged correctly. Internally, the XBRL Engine uses the InlineXbrlValueTransformer class to transform values. It offers public methods to test the transformation of values.
// A unit is required for monetary facts:
Unit unit = inlineGenerator.GetOrAddUnit(new XmlQualifiedName("EUR", XbrlBaseConstants.Iso4217));
Element element = taxonomy.GlobalElements["ifrs-full:ProfitLoss"];
Context context = inlineGenerator.AddContext(element, "AMANA", "LEI", new System.DateTime(2017, 1, 1), new System.DateTime(2017, 12, 31));
XmlElement assets = doc.SelectNodes("//xhtml:td/xhtml:p/xhtml:span", inlineGenerator.InlineXbrlDocument.NamespaceManager)[7] as XmlElement;
InlineNonFraction assetsFact = inlineGenerator.TagNonFractionItem(assets, element, context, unit, -6, 6);
Element revenue = taxonomy.GlobalElements["ifrs-full:Revenue"];
inlineGenerator.AddHiddenNumericFact(revenue, context, -1123123.23m, unit, 2);
Element d = taxonomy.GlobalElements["ifrs-full:DisclosureOfFeeAndCommissionIncomeExpenseExplanatory"];
XmlElement note = doc.SelectNodes("//xhtml:div", inlineGenerator.InlineXbrlDocument.NamespaceManager)[1] as XmlElement;
InlineNonNumeric disclosureFact = inlineGenerator.TagNonNumericItem(note, d, context, true);
// Finally, save the document
inlineGenerator.InlineXbrlDocument.Save("small-inline.docx.xhtml")
Tag Footnotes
The XBRL Engine offers methods to insert footnotes to existing facts. This can be done by tagging the footnote itself, and then adding a relationship between the footnote and an unlimited numbers of facts (continuing the example from above):
// Select the footnote body text from the XmlDocument:
XmlElement footnoteBody = doc.SelectNodes("//xhtml:td/xhtml:p/xhtml:span", inlineGenerator.InlineXbrlDocument.NamespaceManager)[7] as XmlElement;
//Tag and connect the footnote text to the two facts from above:
inlineGenerator.AddInlineFootnote(footnoteBody , CultureInfo.GetCultureInfo("en"), new List<InlineFact>() {assets , disclosureFact });
Converting and Validating Inline XBRL Documents
InlineXBRLDocuments can be validated by nameing the validate method. Keep in mind that the XHTML validaton is loading the full XML scheme, which might take some time.
// First, all XML documents of one iXBRL report have to be loaded into a list:
List<XmlDocument> instanceDocs = new List<XmlDocument>();
foreach (string instance in Directory.GetFiles(@"C:\xbrlReport", "*.xhtml"))
{
XmlDocument xmlDocument = new XmlDocument(Processor.NameTable) { PreserveWhitespace = true };
xmlDocument.Load(instance);
instanceDocs.Add(xmlDocument);
}
InlineXbrlDocument inlineDoc = InlineXbrlDocument.Load(Processor, instanceDocs);
// Validate iXBRL 1.1
inlineDoc.Validate(validateXbrlTaxonomies: false, attachResultsToFacts: true);
// Validate XHTML
inlineDoc.ValidateXhtml(attachResultsToFacts: true);
// Writing validation results to console output:
foreach (IValidationResult result in inlineDoc.DocumentResultSet.GetItems())
{
Console.WriteLine(result.Message);
}
To convert InlineXBRLDocuments to normal XBRLDocuments and to perform validation of the formulas the ConvertToXBRLDocuments can be used. All it takes it the return a dictionary of Dictionary<string, XbrlDocument>, where the string represents the target document (in case of default target documents, its an empty string):
foreach (var convertedDoc in doc.ConvertToXbrlDocuments())
{
// Save file on disk:
convertedDoc.Value.Save($"converted_{convertedDoc.Key}.xbrl");
// Perform normal XbrlDocument validation, including Formula:
convertedDoc.Value.ValidateIncludingFormula(false, false, false);
}
For more information about the validation of XBRLDocuments, see chapter above.
Create or Extend Taxonomies
Some reporting, like ESEF and SEC reporting, require to extend a taxonomy. Reports for those requirements use a custom taxonomy, which is based on another taxonomy (like IFRS taxonomy). This means that the elements from the base taxonomy can be used, but the custom taxonomy can also define additional elements which are published in the report. With the AMANA XBRL Engine it is possible to generate such a taxonomy extension.
According to the ESEF, reporting requirement extension elements must also be anchored. This means that extension elements must be linked to an existing element of the ESEF taxonomy. Those anchors can also be generated using the AMANA XBRL Engine.
The namespace AMANA.XBRL.Engine.TaxonomyCreator contains classes for generating taxonomy extensions. The general process for creating a taxonomy extension is:
- Use the TaxonomyExtensionBuilder to create a XbrlTaxonomy object in memory and add all extension elements to the taxonomy.
- Use the TaxonomyCreator to save the XbrlTaxonomy object as XML files.
TaxonomyExtensionBuilder
The TaxonomyExtensionBuilder can be used to create a taxonomy extension based on an existing taxonomy. The constructor takes the following parameters:
| Type & Name | Description |
|---|---|
| Processor processor | A processor which is used for loading the base taxonomy. |
| string targetNamespace | The target namespace of the taxonomy extension. |
| string targetNamespacePrefix | The XML namespace prefix for the target namespace which is used within the taxonomy extension. |
string baseNamespace | The namespace of the base taxonomy. |
| string baseTaxonomyUri | The URI of the base taxonomy. This URI will be used for loading the base taxonomy using the passed processor. |
| string fileNameBase | The name of the XSD file of the taxonomy extension. |
Add Elements
New elements are added to the taxonomy extension by using the builder's AddElementToTaxonomy method. Most elements are new concepts/metrics for which values can be reported. The following parameters must be passed when creating a new element.
| Type & Name | Description |
|---|---|
| string id | The ID of the element. The ID must be unique in the whole taxonomy set, i.e. no other element defined in the extension taxonomy and no other element in the base taxonomy can have the same ID. Therefore it is recommended to add a prefix to the extension element to avoid clashes with the base taxonomy. It must be a valid ID according to the XML standard, i.e. it must be an NCName. |
| string name | The name of the element. |
| XmlQualifiedName typeName | The type of the value which can be reported for this element. The value is an XML qualified name which resolves to a definition of the type. Use the attributes of the class TaxonomyExtensionBuilder to use common type definitions from the XBRL specifications, e.g. MonetaryItemType. |
| XmlQualifiedName substitutionGroup | The substitution group of the element, which defines the type of the element. The value is an XML qualified name which resolves to a definition of the substitution group. Use the attributes of this class to use common substitution group definitions from the XBRL specifications, e.g. ItemSubstitutionGroup can be used for adding metrics. |
| bool isAbstract | Defines if the extension element is abstract. It is not possible to report values for abstract elements. Abstract elements can be used for structuring the linkbases of the taxonomy, in which elements are grouped in hierarchies. Some elements, like dimensions and hypercubes, must always be abstract. |
| bool isNillable | Defines if xsi:nil can be reported for the extension element. |
| Element.ElementBalanceType balanceType | Defines the balance type of the extension element (credit, debit or unknown). |
Element.ElementPeriodType periodType | Defines the period type of the extension element, which can be instant, duration or unknown:
|
Add Roles
Elements are grouped in roles. A role is a group of related elements, e.g. all elements used in a single table or chapter. A role could be "Changes in Equity" or "Property, plant and equipment". To add a new role type, use the builders' AddRoleType method, which takes the following arguments:
| Type & Name | Description |
|---|---|
| string id | The ID of the new role. |
| string definition | A string describing the role. |
| string filename | The name of the taxonomy extension XSD file. |
| string roleUri = null | The role's URI. If no value is passed for this attribute, the default value is used, which is a concatination of the target namespace of the taxonomy, the string "/roles/" and the ID of the role, e.g. "http://amana.com/xbrl/roles/ID". |
Add links and linkbases
Roles can have multiple links. A link contains hierarchical relationships between elements in this role. There are different types of links and a role can have multiple types of links:
- Presentation link: Defines how elements should be displayed.
- Calculation link: Defines of which elements an element is composed of, e.g. "Assets" is composed of "Current Assets" an "Non-current Assets".
- Label link: Defines labels for elements. A single element can have multiple lables, e.g. different languages or different types of labels (a standard label, a terse label, a verbose label, ...).
- Definition link: Defines hypercubes.
All links of the same type are defined within a linkbase. To create a link for a role, together with a linkbase, the method AddLinkbaseLinkWithRefs can be used, which takes the following arguments:
| Type & Name | Description |
|---|---|
| XbrlRoleType roleType | The role for which a linkbase should be added. |
| XbrlLinkType linkType | The type of the linkbase. |
| BaseLinkbase linkbase = null | The base linkbase in which the link will be added. If no value is passed, a new linkbase will be added. |
Add Arcs
Links contain hierarchical relationships between elemens. A single relationship is defined by an arc. This arc defines a relationship between a from element (or parent element) and a to element (or child element). Based on the type of linkbase, a different type of arc is added to the linkbase and different attributes must be defined for the arc. To add an arc to an existing link, use the builder's AddArc method. This method takes the following arguments:
| Type & Name | Description |
|---|---|
| ILInkbaseLink link | The link to which an arc should be added. |
| Element fromElement | The arc's from element. |
| Element toElement | The arc's to element. |
| string arcRole | The type of relationship between the from and to element. The value is an URI of an arcrole defined in the taxonomy. Use the constants defined in the class AMANA.XBRL.Engine.XbrlArcRoleConstants to use common arc roles defined by XBRL specifications. |
| decimal? order = null | The arc's order attribute which defines the order in which to elements with the same from element should be displayed/evaluated. If there are multiple arcs with the same from element in a link, the children of the different arcs are ordered by the order. If the arc has no order, the default value 1 is assumed. |
| decimal weight = 1 | The weight attribute must appear on calculation arcs. Calculation arcs defines which to elements sums up to a certain from element. The weight attribute defines a multiplicator which must be applied before adding it's value to the total sum (usually 1 or -1). The XBRL specification defines constraints on valid values for the weight attribute based on the balance attribute of the from and the to element:
If the arc is not a calculation arc, this parameter will be ignored. |
| bool closed = false | The closed attribute only appears on definition arcs. It can appear on arcs with the all arc role and arcs with the not all arc role for defining hypercubes:
If the arc is not a definition arc, the value will be ignored. |
| string contextElement = null | The context element attribute only appears on definition arcs. It appears on arcs with the all arc role and arcs with the not all arc role for defining hypercubes. It defines which container of the context dimension information should be stored for reporting a value for this hypercube. The only valid values are "segment" and "scenario". For definition arcs which have neither all nor not all arc role, nothing should be passed. If the arc is not a definition arc at all, the value will be ignored. |
| string preferredLabelRole = null | Defines the URI of the element's label which should be used when displaying the item in the relationship defined by the arc. The class AMANA.XBRL.Engine.XbrlBaseConstants defines URIs of common label roles. |
Anchoring
For ESEF it is necessary to create anchors for extension elements. Anchors are references to elements defined in the ESEF taxonomy. There are two types of anchors: widers and narrowers. Wider anchors are used to link the extension element to an taxonomy element having the closest wider accouting meaning/scope. Narrower anchors are used to link extension elements to taxonomy elements having narrower accounting meaning/scope.
In the taxonomy extension those anchors are represented by arcs with a special arcrole. Those arcs can be added using the metod AddAnchoredDefinitionArc defined in the TaxonomyExtensionBuilder class. This method takes the following arguments:
| Type & Name | Description |
|---|---|
| DefinitionLink link | The link in which the anchor (arc) will be added. |
| Element anchorFrom | The arc's from element:
|
| Element anchorTo | The arc's to element:
|
| decimal order | The arc's order attribute. If there are multiple arcs with the same from element, the order attribute defines the order in which the to elements should be displayed when using XBRL software. |
| string widerNarrowerCustomRoleUri = null | The arc's arc role URI. If no value is provided, the value "http://www.esma.europa.eu/xbrl/esef/arcrole/wider-narrower" will be used as arc role URI, which is the arc role URI which should be used for anchoring arcs according to the ESEF reporting requirements. |
Using TableModels to generate Tables from the Table Linkbase
Namespaces
Classes for handling tables are defined in AMANA.XBRL.Engine.Plugin.TableLinkbase, which is defined in a .dll file with the same name. In addition, AMANA.XBRL.Engine.Plugin.NonTableLinkbaseTable is used for calling several helper methods, which is defined in the equally named .dll file.
Filing Indicator Generation
Filing indicators are used to indicate what tables (data from the tables) are reported in the instance file. Filing indicators can be retrieved from a supplied taxonomy. A common practise is to employ the following statements:
Element fIndicatorsElement = taxonomy.GlobalElements["find:fIndicators"]; Element filingIndicatorElement = taxonomy.GlobalElements["find:filingIndicator"]; Tuple fIndicators = instance.AddTupleToInstance(fIndicatorsElement);
In order to make the instance file be conform with the filing rules, filing indicators must refer to a separate context element. Such can easily be done using the following code:
Context cf = instance.AddInstantContext("c-filingIndicators", DateTime.Now, "AMANA", "http://companyName.de");
The AddInstantContext(string id, DateTime instantDate, string identifier, string identifierScheme) method accepts the following parameters: string id: The unique id of the context, DateTime instantDate: The instant date of the duration period, string identifier: The identifier of the context, string identifierScheme: The identifier scheme of the context.
A Filing indicator is a special kind of fact, thus, it is appended to the instance the same way as an ordinary XBRL fact:
Fact filingInd = new Fact(InstanceDocument.XbrlInstances, filingIndicatorElement, cf); filingInd.Value = tableResolvedTableHierachy.ParentTable.FilingIndicatorLabel.InnerText; instance.AddFactToTuple(fIndicators, filingInd);
tableResolvedTableHierachy is the instance of TableResolvedTableHierachy class representing the resolved XBRL table hierarchy. Usually tableResolvedTableHierachy is pulled out from role.ResolvedTableHierachies() method where role is a member of Taxonomy.GlobalResolvedRoleTypes collection. Below is the sample how filing indicators look like in the instance file:
<find:fIndicators> <find:filingIndicator contextRef="c0">C_26.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_27.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_28.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_29.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_30.00</find:filingIndicator> <find:filingIndicator contextRef="c0">C_31.00</find:filingIndicator> </find:fIndicators>
TableModel
Note: Table Model here refers to the Table Layout Model from the XBRL specification.
A taxonomy can contain table linkbases, which defines the structure of tables. These tables can be read and visualized by the XBRL Engine. The XBRL tables are represented as objects of type TableModel. These are Excel-like objects with rows, columns and cells, allowing easy rendering, mapping and editing of data. To generate a TableModel, first a BreakdownModel is required which describes how each axis looks like. The BreakdownModel usually is based on the TableLinkbase model and can be transformed into Table models by the TableModelGenerator ( GenerateTableLayoutModels() ). This generates one Tablemodel per Z-Axis.
A direct TableModel creation is demonstrated below:
TableModel model = new TableModel(Guid breakdownModelGuid, string tableId, IFactContainer factContainer, List<StructuralNode> zAxisConstraint, XbrlTaxonomy xbrlTaxonomy, Dictionary<XmlQualifiedName, List<IFact>> prefilteredFacts, List<ILabel> tableLabels, string filingIndicator, bool isOpenColumn, bool isOpenRow, UsedTableGenerator breakdownModelType)
tableId is the table's identificator, factContainer - the fact container (e.g. XbrlInstance), zAxisConstraints - a list of List<StructuralNode> type holding Z-Axis members (for non-Z-Axis tables should be omitted, null to be used instead), taxonomy - XbrlTaxonomy object, prefilteredModelFacts - a list of List<IFact>> type containing Facts specifically for this model (Can be avoided. null to be used instead).
The TableModel class shows off following properties
- BreakdownModelType: Enum which defines how the table should be generated. The option are "TableModel" - the generator uses the table model to generate a table, "DimensionModel" - the generator uses the hypercubes to generate a table and "PresentationModel" - the generator uses the presentation linkbase to generate a table.
- Columns: Contains all columns available in the table.
- FactContainer: The collection of facts from which data was fetched when populating the table’s cells. The FactContainer is usually the instance file, which contains all reported business data. Property of IFactContainer type (Interface) used to hold Facts which can be used to populate TableModels with data (out of Facts) later on. Moreover, FactContainer property can be set to XbrlInstance object by virtue of the IFactContainer implementation.
- FilingIndicatorLabel:
- FirstHeaderCell: Property denoting first Header Cell. Might be usefull for custom Table Model visualisation.
- GetCellData: Delegate of GetCellDataDelegate type used to populate table cells with their values (per callback).
- HasCoordinateCodeLabels: Is true, if at least one RcCode label exists for a row/column.
- HeaderCells: The cells, which contains column/row header labels.
- HeaderColumns: Gets the Header Columns count.
- HeaderRows: Gets the Header Rows count.
- Id: Property of System.Guid type assigned to a TableModel on creation.
- IsOpenColumn: States that Table Model is non-closed and facilitates open Columns (no strict column structure defined).
- IsOpenRow: States that Table Model is non-closed and facilitates open Rows (no strict row structure defined).
- PrefilteredFacts: The prefiltered model facts.
- Rows: Contains the rows (row collectio of List<TableRow> type) available in the generated table.
- SelectedZAxisHash: Gets the hash of current Z-Axis member key.
- TableId: Property disclosing the Table Id (Table Name) of a TableModel as defined in Taxonomy.
- TableLabels:
- Taxonomy: Property holding XBRL Taxonomy (typeof XbrlTaxonomy).
- ValueCells: Property of IEnumerable<TableValueCell> type holding the cells which can contain facts/business data, as well as the data itself from the FactContainer, if existing.
- ZAxesConstraints: Dicloses the list of contraints (typeof ConstraintList) placed on ZAxes members (as per Taxonomy).
- ZAxesCoordinateCode:
- ZAxesKey: States Z-Axis key of current Z-Axis member. Can be used for mapping purposes.
- ZAxesNodes: Property of List<StructuralNode> type holding current ZAxis members for this model if applicable. (Previously SelectedZAxisMember).
- ZAxesNodesByBreakdown: Property of Dictionary<Breakdown, StructuralNode> type keeping track of ZAxis members grouped by breakdown.
To generate all possible tables of an instance document, you can use the helper method GetBestMatchingTableModels, which will return a list of TableModels:
var processor = new Processor(); var xbrlDocument = processor.LoadXbrlDocument(@"C:\path\xbrlInstance.xml "); var models = xbrlDocument.GetBestMatchingTableModels( CultureInfo.CurrentCulture, Mode.View, OpenTableHeaderRenderingMode.ViewMode) .ToList();
Three parameters are passed to this method:
- A culture which is used for selecting labels used in the table, e.g. the descriptions in column and row header cells. The taxonomy can define labels for multiple languages. The engine will look for lables, which matches the given culture. If no matching label is found, the engine will look for an english label.
- There are two different modes: view mode and edit mode. The view mode will create a table model which is optimized for viewing data, the edit mode will create a table for editing purposes.
- A XBRL taxonomy can define tables, in which the user itself can add rows. These tables are called open tables. For open tables, you can add additional header cells. Using the third parameter, you can define in which modes (view mode, edit mode, never) you want to display these additional cells.
TableModelGenerator
XBRL table models defined in the taxonony can be generated using the TableModelGenerator class of the AMANA.XBRL.Engine. TableModelGenerator class facilitates certain public properties enabling control over the table generator's behaviour.
- Culture: Culture object used to display the corresponding labels on the TableModel (e.g. set Culture "en" to get a English table presentation or "de" for a German one). The labels need to be available in the Culture language, otherwise default labels will be displayed. Culture by default is system-dependent.
- DisableSorting: Disables table sorting based on column values.
- DisplayRcCodeAsChild: If true RC codes row/column are added after header rows/columns.
- FormulaProcessor:
- GetCellData: The delegate of TableModel.GetCellDataDelegate is called every time a nw adding TableValueCell to the model. Note: Default value of the property is null.
- HeaderRenderingMode: Defines when a header cell with the description of an open typed aspect will be rendered. There are three modes: "Never" - The node will be never visible as header cell, "ViewMode" - The node will appear as header cell in (TableMode) view mode and "EditMode" - the node will apper as header cell in (TableMode) edit mode.
- IncludeStructuralNodes: Static property controlling inclusion of structural nodes during table model generation. Usually only used for debugging purpose, false by default.
- PredefinedOpenAspectMembers: Can be used to predefine open aspects, enabling generation of models/aspects without facts. PredefinedOpenAspectMembers property is defaulted to an empty dictionary of <OpenAspectStructuralNode, List<StructuralNode> type.
- PredefinedTypedDimensionAxisMemberPairs: Serves same purpose as previous property but rather applies to Typed Dimension Table Models. The property is used to populate Open Table with sample row/column/ZAxis. Note: Default value of the property is null.
- PredefinedTypedDimensionAxisMemberPairsByZAxis: Can be used to predefine combinations of open aspects for specific Z-Axis-Tables.
- TableGenerator: Defines what part of the taxonomy should be used to generate a table model.
- TableMode: Property accepting Mode.View (Default) or Mode.Edit allowing table model viewing or editing.
- Taxonomy: Sets the base Taxonomy. Additionally, can be set through constructor.
Create a TableModelGenerator from a Taxonomy
TableModelGenerator generator = new TableModelGenerator(new System.Globalization.CultureInfo("en-US"), taxonomy);
The first parameter accepts an object of the CultureInfo class which is used for the display label language and the second one is a taxonomy object (of type XbrlTaxomy). Additionally, there are 2 other constructor overloads which require a XbrlTaxomy. One is accepting the instance of XbrlTaxonomy class, in that case the generator's culture will be defaulted to CultureInfo.CurrentCulture. The second one takes three parameters, CultureInfo culture, XbrlTaxonomy taxonomy and OpenTableHeaderRenderingMode headerRenderingMode. The OpenTableHeaderRenderingMode is set to EditMode as default.
The following example shows the table renderings with HeaderRenderingMode activated and deactivated.
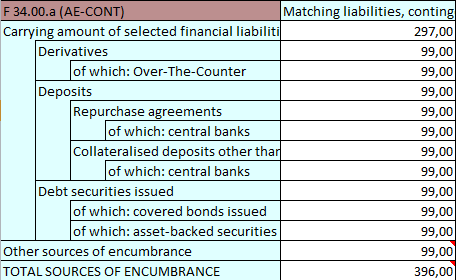
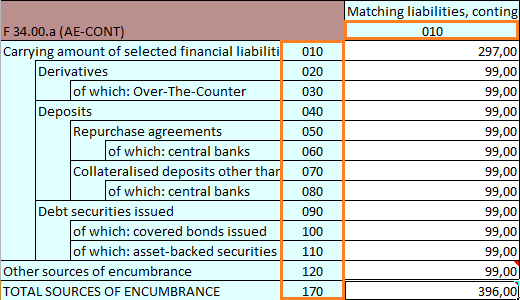
Create a TableModelGenerator from a XBRL Instance
It is also possible to to generate Table Model(s) out of a XBRL instance.
TableModelGenerator generator = new TableModelGenerator(instance);
Here the instance object represents the XbrlInstance object. As with seen before, the culture will be defaulted to CultureInfo.CurrentCulture and the instance's first taxonomy will be used.
Table Model generation
Table Model generation, using AMANA.XBRL.Engine, is a two-step process involving creation of two separate Table Models: Structure and Layout. The structure model can be created using the GetResolvedStructureModels method as follows:
foreach (TableStructureModel model in t.GetResolvedStructureModels(InstanceDocument.XbrlInstances)){}
InstanceDocument.XbrlInstances is an XbrlInstance document. t is an object of type TableResolvedTableHierarchy.
In order to generate Layout Table Models, the following statement should be used:
IEnumerable<TableModel> generatedModels = generator.GenerateTableLayoutModels(model, InstanceDocument.XbrlInstances);
model is an instance of TableStructureModel class and InstanceDocument.XbrlInstances is an XBRL instance (of type XbrlInstance) being passed. A complete sample of how table models can be generated out of a taxonomy is demonstrated below:
List<TableModel> models = new List<TableModel>();
List<string> includedFilingIndicators = new List<string>();
foreach (AbstractXbrlResolvedRoleType role in _taxonomy.GlobalResolvedRoleTypes)
{
foreach (var t in role.ResolvedTableHierarchies())
foreach (TableStructureModel model in t.GetResolvedStructureModels(_instanceDocument.Instance))
{
messenger.SecondMessage("Generating table " + model.TableLabel);
TableModelGenerator generator = new TableModelGenerator(CultureInfo.CurrentCulture, _taxonomy)
{
TableMode = Mode.Edit
};
if (model.IsOpenTable)
generator.SetPredefinedOpenAspects(model, _instanceDocument.Instance);
if (model.IsOpenTable)
AddTypedExampleToGenerator(model, generator);
IEnumerable<TableModel> generatedModels = generator.GenerateTableLayoutModels(model, _instanceDocument.Instance);
foreach (TableModel layoutModel in generatedModels)
{
foreach (TableValueCell cell in layoutModel.ValueCells)
if (cell.MatchingFacts.Count == 0)
{
counter++;
string exampleValue = counter.ToString();
switch (cell.Concept.TypeNameShort.ToLower())
{
case "string":
exampleValue = "string" + exampleValue;
break;
case "boolean":
exampleValue = "false";
break;
case "qname":
case "enumeration":
exampleValue = (cell.Concept as EnumerationElement).MemberElements.FirstOrDefault().NameQualified;
break;
case "date":
exampleValue = DateTime.Now.ToString("yyyy-MM-dd");
break;
case "integer":
case "decimal":
case "monetary":
exampleValue = exampleValue;
break;
case "percent":
exampleValue = "0.9999";
break;
default:
exampleValue = "?";
break;
}
GetNewFactForTableValueCell(cell, exampleValue);
}
models.Add(layoutModel);
}
}
}
The AddTypedExampleToGenerator method is defined as follows:
private void AddTypedExampleToGenerator(TableStructureModel model, TableModelGenerator generator)
{
if (generator.PredefinedOpenAspectMembers == null)
generator.PredefinedOpenAspectMembers = new Dictionary<OpenAspectStructuralNode, List<StructuralNode>>();
foreach (OpenAspectStructuralNode node in model.OpenStructuralNodes)
if (node.AspectType == AspectType.TypedDimension && !generator.PredefinedOpenAspectMembers.ContainsKey(node))
generator.PredefinedOpenAspectMembers.Add(node, new List<StructuralNode> { new TypedClosedStructuralNode(node.ParentBreakdown, null, new TypedDimensionConstraint(node.Dimension, "example"),
new List<ILabel> { new DisplayLabel("example", CultureInfo.CurrentCulture.Name) }, false) });
}
Due to the fact that Open Tables without any values for OpenAspects do not contain ValueCells, which can be edited later, such must be constructed in order to generate a table model with visible ValueCells. This function adds default values for all OpenAspects without values.
Supplementary, the Table Model Generator facilitates the GenerateTableModelWithZNodeAsXAxis method which might be used to flatten Z-Axis Table Model to ordinary 2-dimensional tables. The function generates a table with only one axis. This axis will be displayed as the table's x axis.
TableModel firstTableModel = tableModels.First(); TableStructureModel structureModel; TableModelGenerator generator = new TableModelGenerator(System.Threading.Thread.CurrentThread.CurrentCulture, firstTableModel.Taxonomy); TableModel zAxisModel = generator.GenerateTableModelWithZNodeAsXAxis(structureModel, firstTableModel.Taxonomy, firstTableModel.ZAxesNodes, firstTableModel.FactContainer);
structureModel is of type TableStructureModel, firstTableModel.Taxonomy is of type XBRLTaxonomy, firstTableModel.ZAxesNodes is of type List<StructuralNode> and firstTableModel.FactContainer is of type IFactContainer.
Using the GetCellDataDelegates
As mentioned in the previous section, TableModelGenerator exposes the GetCellData Property which has the type of TableModel.GetCellDataDelegate. GetCellDataDelegate is defined as follows:
public delegate IFact GetCellDataDelegate(TableValueCell cell, TableRow row);
Once the GetCellDataDelegate is set (assigned with a method following above signature), it will be fired every time when new TableValueCell is added to the model. Alternatively stated, the GetCellDataDelegate delegate is a common way to populate a Table Model with data.
IFact
As it is mentioned in the previous section, the GetCellDataDelegate returns an object of the IFact type which is an interface defining a skeleton for the XBRL fact and facilitating the following properties:
- ConceptLocalName: string-based name of the XBRL concept assigned with the fact.
- ConceptQName: XBRL concept expressed by means of XmlQualifiedName.
- EndDate: A DateTime defining the end date of the context under which a fact is reported.
- EntityIdentifier: String Entity Identifier of the context under which a fact is reported.
- EntitySchema: String Entity Schema of the context under which a fact is reported.
- ExactValue: An exact value of the fact in terms of decimal data type.
- ExplicitDimensionMember: A collection of Dictionary<XmlQualifiedName, XmlQualifiedName> type listing the explicit dimensions constraining the fact.
- HasComment: Determines if the object has comments or footnotes attached to it.
- HasManualFormatting: Specifies whether a manual formatting was applied.
- Id: Fact can have an ID, which is e.g. used when the Fact has a footnote. The footnote is tied to a locator that references a fact using its ID.
- IsForever: True If fact's period to be expressed as forever.
- isNil: Facts can be reported as nil to explicitly state that no value should be reported for this metric. But many regulators prefer not to report a fact instead of reporting a nil fact.
- RoundedValue: A rounded value of the fact (in case when fact is numeric) in terms of decimal data type.
- StartDate: A DateTime defining the start date of the context under which a fact is reported.
- TypedDimensionMember: A collection of Dictionary<XmlQualifiedName, string> type listing the typed dimensions constraining the fact.
- TypeName: XmlQualifiedName-expressed type name.
- UnitID: The ID of the Unit assigned with a fact.
- UnitMeasure: Unit measure assigned with a fact (e.g. pure). Expressed in XmlQualifiedName.
- Value: String value of the fact.
- XmlPrefixAndName: Namespace prefix and name of the XBRL concept. (For backward compability).
Additionally, the IFact defines the GetDimensionMemberPairs() method and the GetRoundedValue(CultureInfo culture) method signature. The concrete implementation should return the dimension members constraining a fact respectivly the rounded value.
Using the OpenAspect Nodes (Typed Dimension)
The TableStructureModel.IsOpenTable property determines whether a table is opened or closed. If a table model exposes open structure, the following property of type List<OpenAspectStructuralNode> can be used to retrieve the open aspects forming such structure: OpenStructuralNodes. Disregarding what type of open structure (open column, open row or open Z-Axis) the table has, OpenStructuralNodes property will list all available open aspect nodes. The Following snippet illustrates how to include open aspects to a model:
TableStructureModel model;
TableModelGenerator generator;
if (generator.PredefinedOpenAspectMembers == null)
generator.PredefinedOpenAspectMembers = new Dictionary<OpenAspectStructuralNode, List<StructuralNode>>();
foreach (OpenAspectStructuralNode node in model.OpenStructuralNodes)
if (node.AspectType == AspectType.TypedDimension && !generator.PredefinedOpenAspectMembers.ContainsKey(node))
generator.PredefinedOpenAspectMembers.Add(node, new List<StructuralNode> { new TypedClosedStructuralNode(node.ParentBreakdown, null, new TypedDimensionConstraint(node.Dimension, "example"), new List<ILabel> { new DisplayLabel("example", CultureInfo.CurrentCulture.Name) }, false) });
model is an instance of TableStructureModel class and generator of TableModelGenerator. Additionally, TableModel class informs whether a model is open or closed is by exposing IsOpenRow and IsOpenColumn properties. Z-Axis can be tracked used ZAxesNodes property. A simple check can be used to find out whether a table additional dimension has a Z-Axis:
if (model.ZAxesNodes != null) //drilled down processing...
Optionally, ZAxis can be set via TableModel constructor's zAxisConstraint parameter (if applicable). The name of Z-Axis can be retrieved using following code:
var firstMember = member.FirstOrDefault(); var zAxisName = String.IsNullOrEmpty(firstMember.StandardLabel) ? firstMember.StandardLabel : firstMember.CoordinateCodeLabel;
member is a List<StructuralNode> collection (e.g. model.ZAxesNodes).
Note: A XBRL table might be designed such way to facilitate multiple ZAxis members, thus, a statement as model.ZAxesNodes.FirstOrDefault() will lead to dispersancy with underlying taxonomy.
Generate a table with predefined explicit Z-axis values
If a TableStructureModel has open Z axis members, the TableModelGenerator's PredefinedOpenAspectMembers property can be used to define values for each open Z axis node. The code snippet below demonstrates how to add such predefined values for a table with two open explicit Z-axis nodes.
// Load the 3.0 Renumeration High Earners taxonomy.
string entryPoint = "http://www.eba.europa.eu/eu/fr/xbrl/crr/fws/rem/gl-2014-07/2021-02-28/mod/rem_he.xsd";
var processor = new Processor();
XbrlTaxonomy taxonomy = processor.ReadXbrlTaxonomy(entryPoint);
// Get the role for table R 04.00, which contains the data for generating the table.
string roleUri = "http://www.eba.europa.eu/xbrl/crr/role/fws/REM/gl-2014-07/2021-02-28/tab/R_04.00.a";
AbstractXbrlResolvedRoleType role = taxonomy.GlobalResolvedRoleTypesByUri[roleUri];
// Get the table hierarchy for table R 04.00, which defines the structure of the table.
TableResolvedTableHierarchy hierarchy = role.ResolvedTableHierarchies().First();
// Generate a table structure model based on the table hierarchy which is used as a template for actual tables.
TableStructureModel structureModel = hierarchy.GetResolvedStructureModels(null).First();
// Create a TableModelGenerator, which is responsible for generating actual tables based on table structure models.
var generator = new TableModelGenerator(taxonomy);
// The generator's GenerateTableLayoutModels method generates table models based on a fact container (usually an XBRL instance).
// Based on the fact container, cells/nodes with values for open nodes within the table structure model are added to the table model.
// In case of tables with open z axes, no table will be generated if no fact container is passed,
// because no value for the open z axes are present.
// However, it is possible to define values that should be added for open nodes on a specific axis.
// To do so, a set of predefined values is added to the generator's PredefinedOpenAspectMembers property.
// To identify the open nodes, their dimension names are used.
var paymentBandDimensionName = new XmlQualifiedName("PYB", "http://www.eba.europa.eu/xbrl/crr/dict/dim");
var eeaStateDimensionName = new XmlQualifiedName("HEL", "http://www.eba.europa.eu/xbrl/crr/dict/dim");
// Also the values have names which can be used to identify them.
// Below are the names of the values which should be added to the z axes.
var paymentBandDimensionMembers = new List<string> {"x5", "x6"};
var eeaStateDimensionMembers = new List<string> {"DE", "FR", "IT"};
// To get all open nodes on each z axis breakdown, iterate through each z axis breakdown.
foreach (Breakdown breakdown in structureModel.ZAxesBreakdowns)
{
// Now iterate through each open node in this breakdown.
// Usually there is only one open node per breakdown.
foreach (OpenAspectStructuralNode openNode in breakdown.OpenStructuralNodes)
{
// Each open node has a specific aspect type which defines what kind of value can be used for this open node.
// In case of table R 04.00, the node type is explicit dimension, i.e. there is a predefined list of valid values.
// Each valid value is an element within a certain dimension.
if (openNode.AspectType == AspectType.ExplicitDimension)
{
List<string> zAxisValuesToAdd;
if (openNode.Dimension == paymentBandDimensionName)
zAxisValuesToAdd = paymentBandDimensionMembers;
else if (openNode.Dimension == eeaStateDimensionName)
zAxisValuesToAdd = eeaStateDimensionMembers;
else
continue;
// Use GetAllExplicitMemberValueElementsWithDefault
// to get all valid values for an explicit dimension open aspect node.
List<Element> validValueElements = TableModelGenerator.GetAllExplicitMemberValueElementsWithDefault(openNode).ToList();
// Each predefined value is a structural node.
// All predefined values are be added to this list.
var predefinedValues = new List<StructuralNode>();
// Fill the predefinedValues list.
foreach (string valueToAdd in zAxisValuesToAdd)
{
// Try to find the element for the predefined value.
Element valueElement = validValueElements.FirstOrDefault(element => element.Name == valueToAdd);
if (valueElement == null)
continue;
// Each structural node has a constraint representing the value for a certain dimension.
var constraint = new ExplicitDimensionConstraint(
dimension: openNode.Dimension,
member: valueElement.QualifiedName,
isDefaultMember: taxonomy.GetDefaultMembersOfDimensions(openNode.Dimension).Contains(valueElement.QualifiedName));
// Create the node for the value and add it to the list of predefined values.
var node = new ExpandedExplicitDimensionNode(
openAspectNode: openNode,
parent: null,
constraints: new ConstraintList {constraint},
labels: valueElement.Labels);
predefinedValues.Add(node);
}
// Add the combination of open node and it's predefined values to the generator.
generator.PredefinedOpenAspectMembers.Add(openNode, predefinedValues);
}
}
}
// When generating the table models, there should be a table for each combination of all predefined z axis members.
// So six tables are generated in total (2 Payment Bands * 3 EEA States)
TableModelList tables = generator.GenerateTableLayoutModels(
breakdownModel: structureModel,
factContainer: null);
Edit and View Modes
Ich denke, man müsste hier genauer erläutern, was die Table Modes bewirken. Einmal werden Typed Dimension Values nicht mehr gemerged (sodass die Zellen einzeln bearbeitbar sind) und die Header Cells werden ggf. anders dargestellt: es gibt einen HeaderRenderingMode der bestimmt, ob über den Typed Dimension Zeilen noch Header Zellen angezeigt werden sollen, die beschreiben, worum genau es sich bei diesem Typed Value handelt, z.B. "Lei Code" über der Spalte mit LEI-Codes.
The TableModelGenerator class facilitates the TableMode property (of Mode type, the enum declaring View and Edit options) which can be used to control table model's access level. In view mode, the values of open aspect nodes can't be edited. Open rows without any facts get eliminated, i.e. they are not shown. In edit mode, the values of open aspect nodes can be edited. All rows are displayed, including rows without any facts. Typed dimension cells will not be merged, thus the single cells are editable.
Also the header cells may be visualized differently, depending on the OpenTableHeaderRenderingMode mode. The OpenTableHeaderRenderingMode can either Never For example, header cells with additional information can be shown above the typed dimension rows. The table model access can either be read-only or edit. Read-only mode is achieved using the following statement:
tableModelGenerator.TableMode = Mode.View;
Edit mode is enabled the below way:
tableModelGenerator.TableMode = Mode.Edit;
This option can be very usefull when developing custom XBRL Viewer application with different access level.
TableValueCell
TableValueCell is one of the key elements in the AMANA.XBRL.Engine, logically representing a Table cell acting under specific set of constraints imposed by the underlying Taxonomy. TableValueCell possesses the following properties:
- Facts: Collection of List<IFact> type representing all facts that fullfill the constraints (as per Taxonomy definition).
- Hypercubes: Collection (of List<HypercubeDimensions> type) containing so-called hypercubes, in XBRL language an ordered list of dimensions (combination of dimensions), where every dimension is used to categorize a fact.
- Id: Cell's id (guid).
- IsValid: Indicates whether a cell contains valid data. Gets set as the result of Custom Validation.
- MatchingFacts: Collection of List<IFact> type representing all facts exactly matching the dimensional constraints and having no other properties. This is the more important collection compared to Facts.
- Model: A table model (typeof TableMode), where cell belongs to.
The most obvious difference between Facts und MatchingFacts can be seen on following sketch. Let's assume that we have Facts constrained by three different dimensions Sales by Gender, Geographical Area and Age.
As it can be noticed, the Fact B is constrained by the additional property Product. As the result, if we had same kind of data, both facts would be in the Facts collection. Fact A would also settle down in the MatchingFacts collection because it is only constraint by the dimensions and no other properties.
- Concept: Property indicating the XBRL Concept associated with given cell (as per Taxonomy definition).
- IsNumeric: Specifies whether cell can hold numeric data.
Generally speaking, a value cell can have different XML data types, see XBRL Specification 2.1 Item Types. Examples:
- monetaryItemType
- stringItemType
- integerItemType
- percentItemType
- booleanItemType
- QName/enumerationItemType
A typical TableValueCell creation is illustrated below:
TableRow row = Rows[i]; //Rows = List<TableRow> TableColumn column = Columns[j]; //Column = List<TabelColumn> List<HypercubeDimensions> hypercubes = TableModelGenerator.GetHypercubes(constraints, Taxonomy).ToList(); ConstraintList constraints = new ConstraintList(); CellBorderStyle cellBorderStyle = CellBorderStyle.Top; TableValueCell cell = new TableValueCell(this, row, column, hypercubes, constraints, cellBorderStyle);
This is an instance of the TableModel class, row - TableRow, column - TableColumn, hypercubes - List<HypercubeDimensions>, constraints - ConstraintList and cellBordersStyle - CellBorderStyle.
TableHeaderCell
TableHeaderCell is a class representing table cells used for displaying meta data such as labels. TableHeaderCell has the following properties:
- CellBorderStyle: Determines which cell boarders are drawn.
- Column: The column of the cell is positioned. If a cell has a column or row span, the top left cell is the referenced cell.
- ColumnSpan: Specifies the number of columns a cell should span.
- Constraints: The constraints the fact for this value must fulfill. E.g. concept or explicit/typed dimension characteristic.
- IsPositionCell: Determines whether a cell represent so-called position cell denoting row/column position number.
- Label: States the label a cell encompasses.
- RcCodeLabel: Property decorating RcCodeLabel.
- Row: The row of the cell. If a cell has a column or row span, the top left cell is the referenced cell.
- RowSpan: Specifies the number of rows a cell should span.
TableHeaderCells are usually created on Table Model generation. However, the class provides public constructor allowing manual creation of such cells.
Excel import/export using TableModels
The TableModel is primarily used to render a table. A TableModel prescribes how the table should be visually represented. A table might be displayed by means of either Excel sheet or Html page.
Using TableViewReportBuilder
The Engine already provides an instrument allowing hassle-free creation of Table views (aka Table renderings). One of them is the TableViewReportBuilder which facilitates Table rendering generation in terms of Excel sheets. The function GenerateTableReport generates an excel report for the given models collection and adds an "General Information" Worksheet with information on the XbrlDocument, if it is set. If validation results exists, it also adds an validation overview worksheet containing all XbrlDocument.DocumentResultSet results. GenerateTableReport takes four parameters:
- List<TableModel> models: A list of models to generate results for
- bool saveAndClose: If true it saves and closes the excel file at the end
- XbrlDocument document(=null): If set, the information from the XbrlDocument are added
- XbrlTaxonomy taxonomy(=null): If set, Excel is not generated from XbrlTaxonomy
A typical usage of the TableViewReportBuilder is illustrated below:
TableViewReportBuilder builder = new TableViewReportBuilder(); builder.AddExcelNames = true; builder.GenerateTableReport(models, saveAndClose); builder.SaveAndClose(); //builder.Filename;
To initiate the Excel rendering process, the GenerateTableReport() method should be called.
Using TableExcelReverseRenderer to convert Excel to XBRL Documents
The class TableExcelReverseRenderer allows to easily convert Excel files (*.xlsx) to XBRL documents (*.xbrl). The following code example shows how to use the function TryAddOrUpdateRenderedExcelToXbrlDocument(ExcelWorkbook workbook, InstanceGenerator generator) to perform the conversion:
TableExcelReverseRenderer renderer = new TableExcelReverseRenderer();
using (ExcelPackage p = new ExcelPackage(new FileInfo("C:\\Example.xlsx")))
{
instanceGenerator = renderer.GetInstanceGeneratorFromWorkbook(p.Workbook, processor);
instanceDocument = instanceGenerator.InstanceDocument as XbrlDocument;
renderer.TryAddOrUpdateRenderedExcelToXbrlDocument(p.Workbook, instanceGenerator);
}
After this, the XBRL document is saved in the instanceDocument variable. instanceGenerator is of type InstanceGenerator, instanceDocument is of type XbrlDocument and processor is of type BinaryCacheProcessor.